DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task
News
Abstract
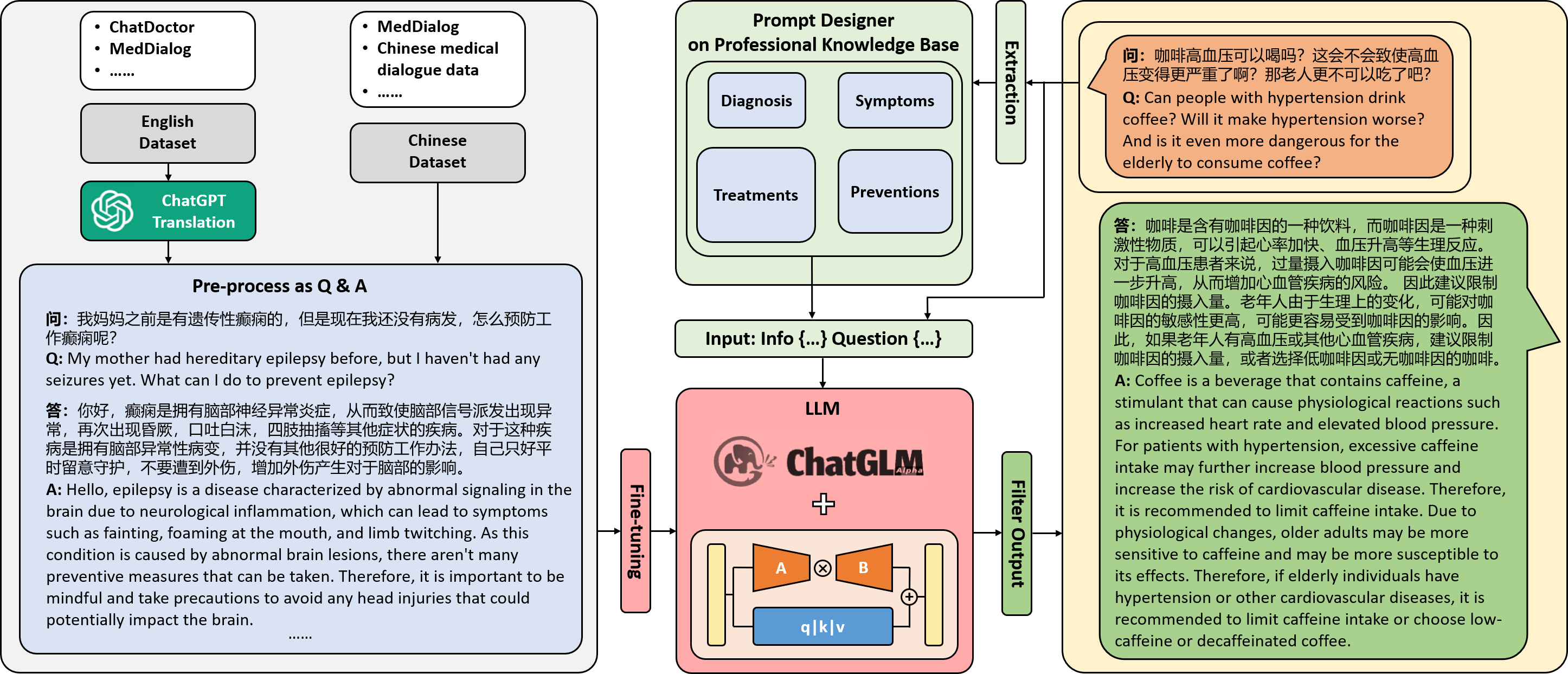
The recent progress of large language models (LLMs), including ChatGPT and GPT-4, in comprehending and responding to human instructions has been remarkable. Nevertheless, these models typically perform better in English and have not been explicitly trained for the medical domain, resulting in suboptimal precision in diagnoses, drug recommendations, and other medical advice. Additionally, training and deploying a dialogue model is still believed to be impossible for hospitals, hindering the promotion of LLMs. To tackle these challenges, we have collected databases of medical dialogues in Chinese with ChatGPT's help and adopted several techniques to train an easy-deploy LLM. Remarkably, we were able to fine-tune the ChatGLM-6B on a single A100 80G in 13 hours, which means having a healthcare-purpose LLM can be very affordable. DoctorGLM is currently an early-stage engineering attempt and contain various mistakes. We are sharing it with the broader community to invite feedback and suggestions to improve its healthcare-focused capabilities
Results



Technical Limitations
- DoctorGLM experiences a loss in capability during logistic training, and it occasionally repeats itself. We suspect that fine-tuning typically incurs a higher alignment cost compared to reinforcement learning with human feedback (RLHF).
- Generating a response takes approximately 15 to 50 seconds, depending on token length, which is significantly slower than interacting with ChatGPT via the web API. This delay is partly due to the chatbot's typing indicator.
- We are currently facing difficulties in quantizing this model. While ChatGLM runs satisfactorily on INT-4 (using about 6G), the trained LoRA of DoctorGLM appears to have some issues. As a result, we are currently unable to deploy our model on more affordable GPUs, such as the RTX 3060 and RTX 2080.
- We have noticed that the model's performance declines with prolonged training, but we currently lack a strategy for determining when to stop training. It appears that cross-entropy is an overly rigid constraint when fine-tuning LLMs.
Citation
@article{xiong2023doctorglm,
title={DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task},
author={Honglin Xiong, Sheng Wang, Yitao Zhu, Zihao Zhao,
Yuxiao Liu, Linlin Huang, Qian Wang, Dinggang Shen},
}